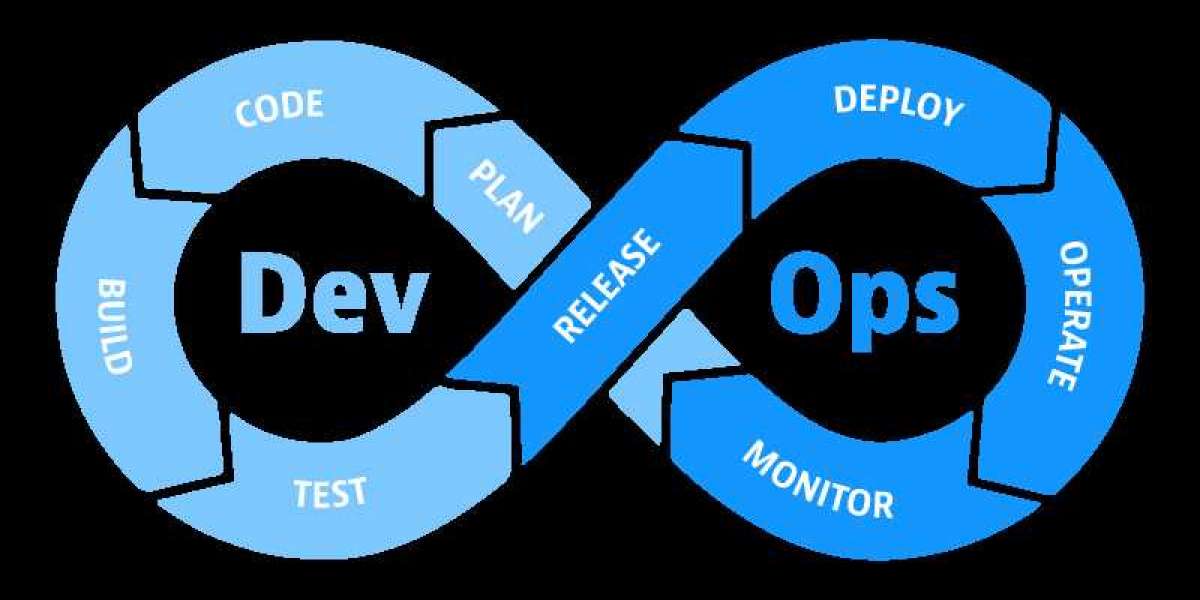
It is an integral part of the DevOps lifecycle that provides essential information that helps us ensure service availability as well as the best efficiency. Operations teams benefit from trustworthy monitoring tools that detect and address the weaknesses or bugs in the application. If you're new to this idea, you might want to consider taking the DevOps Training to increase your understanding.
Tools used: Numerous tools, like Nagios, Splunk, ELK Stack and Sensu are used to monitor the performance of an application. They let us monitor our servers and apps closely to evaluate their health and determine whether they're running efficiently. Any issue discovered through these tools is passed the development team to be fixed in their continuing development phase.
It is crucial to have a plan in place for any problem to be resolved:
- Business Understanding It is important to be clear about the goals you intend to accomplish with your analysis and be sure it's compatible with the company's goals. It is crucial to determine what the client's goals are to minimize savings losses or prefers to predict the cost of a particular product like.
- Data Understanding
After we've finished Business Understanding, the next step is to analyze the data, which includes numerous variables. It is important to focus on the part that focus on when tackling for the business problem. - Preparation of Data
After Data Understanding, the next step is to prepare the data. We can then combine the data sets by connecting them by clearing them and erasing or replacing any data that isn't present.
Create a brand new dataset using the original data that has been sanitized and is able to give greater precision - Exploratory Data Analysis
This process involves the distribution of data within distinct characters. The variables are visually represented through bar graphs. Interactions between different elements are represented using graphic representations like heat maps and scatter plots.
A variety of data visualization techniques are widely used to determine every characteristic and to combine different attributes. - Data Modeling
This is the procedure of choosing the best model for your situation, dependent on whether the issue is one of classification or a regression issue or an issue with clustering.
After we have selected the model family we will choose from the various algorithms within this group, we'll have to be careful when choosing the algorithms we apply and then follow the guidelines. It is vital to alter the parameters of every model to ensure the highest performance. - Model Evaluation
It is scrutinized to see if it's correctly set to go in use. The model is then evaluated using unknown data, and then analyzed by utilizing a carefully planned collection of measurements.
In addition, we have to ensure that the model is in line with the actual situation. If we fail to obtain a satisfactory outcome during the evaluation the model, we'll need to repeat the entire model until the desired quality of metrics is attained. - Model Deployment
This is the most important stage of the life cycle. Each step in the lifecycle of data science described above needs to be worked carefully. If one of the steps is not completed correctly this could affect the next step and this means that the whole effort has to be taken to the next step.
![*Kickin Keto Gummies* Reviews - [Pros or Cons] Does It Really Work or Not?](https://thewion.com/upload/photos/2022/12/Ak98kLOncZo2U8mE5WzW_05_f67dc7e12f2e06c3eef72b1ef97e3738_image.png)






